Initially, I planned for this to be an introduction to the Rust programming language for colleagues at work. However, when looking around online for inspiration, I noticed that one thing there was no shortage of, were Rust introductions. So with that in mind, I thought I would instead focus why I personally find the language interesting.
So I won’t be teaching you how to write Rust. I won’t be giving an overview of the language syntax, or its type system. I won’t be showing you its tooling, or some interesting projects that have been created using the language. And I definitely won’t be trying to convince you to rewrite everything in Rust.
There are already countless videos and articles online which cover these topics, most of which likely do at least a semi-decent job of the task. So if you find your interest piqued at all throughout the duration of this article, then I would encourage you to seek them out, once you’re done reading this one of course!
Instead, my goal today is to try and explain why Rust is both unique and interesting, and why I think you should at least give it a try.
Even if you don’t end up using the language long term, much like learning Haskell or C, you’ll potentially take at least some learnings from it, which can then be applied to projects you tackle in the future.
There will be lies & assembly
I will be glossing over quite a bit of detail throughout this article. There are exceptions to every rule and given the scope of the concepts I will be trying to cover, I won’t be able to describe everything in extreme detail. Hopefully I will still be able to at least get the important points across though.
There will also be a bit of assembly. Only a small amount though. Just enough to show you how something actually works.
I will do my best to try and simplify it, but as long as you have a grasp of some general programming concepts, you should be fine. Assembly is actually a fairly simple language, and it is mostly the things not expressed in the language itself that can make reading it a bit confusing at times.
First a bit of background…
To appreciate what makes Rust interesting, you’ll first need to have at least a rough understanding of a few concepts you have most likely come across before. However, since I am not sure just how much you know, you’ll have to excuse me while I tread over old ground.
Also, if your background is mostly in managed languages like TypeScript, Python or C#, then it could be difficult to see what makes Rust different besides some extra warnings given to you by the compiler, especially given that the syntax of the language will tend to look pretty familiar for the most part.
So to be sure that we all start off on roughly the same page, I’ll briefly go over how programs work in regards to memory. Discussing the stack, the heap and garbage collectors. And most importantly, how Rust manages to get by without one, while still allowing you to work in much the same manner.
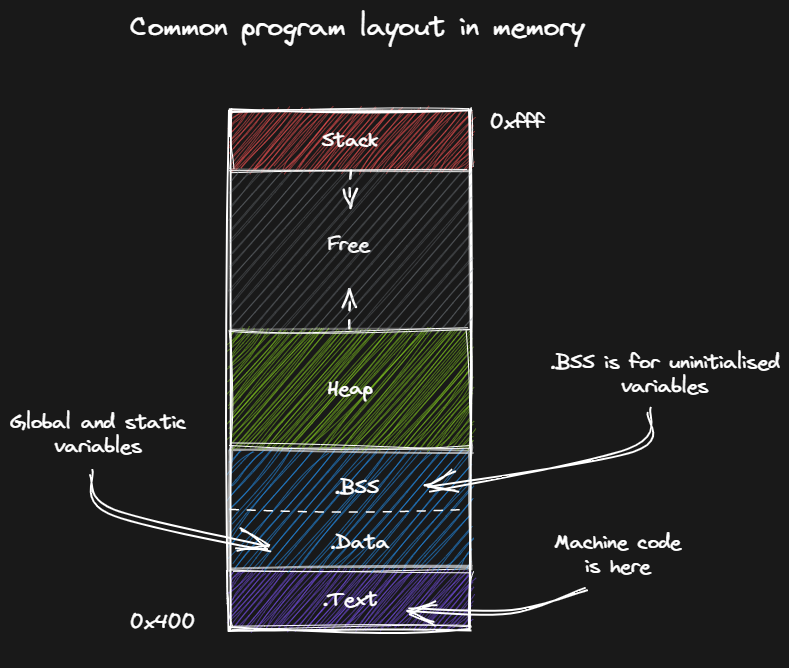
To start, this is a fairly common diagram you’ll see floating around the internet which just illustrates the layout of your program once it is loaded into memory.
You can see at the bottom we have the text section, which holds the machine code instructions the CPU will be running. This is the code you’ve written, after being converted into something the CPU can understand.
But what we’re interested in for now though are the stack and the heap.
What is the stack?
- Allocated from RAM (typically ~1MB - 8MB)
- Requested by and assigned to each thread
- Minimal management overhead (LIFO)
- Allocated in one contiguous block (usually)
- Managed for you by your compiler
- Data on the stack is more likely to be in the cache*
As we saw in the previous image, the stack is stored in RAM.
It is a common misconception that the stack is actually stored somewhere else, perhaps even on the CPU, however this is not the case. Like most things, it is also allocated from RAM.
Each stack instance is typically allocated in one contiguous block. Each block is then assigned to a thread. So if you have an application which is using four threads, you’ll have four separate stacks. Obviously if you don’t have multiple threads, you’ll just get the one.
The stack is typically allocated just the once at the start of each new thread. This memory is only handed back to the OS at the end of the thread’s lifetime, or when your program exits. The advantage here being that it won’t need to make any additional calls to the OS to request more space. Just the one allocation for the lifetime of the thread.
Management of the stack is done using an extremely simple last-in, first-out data structure. This means that the last thing you push onto the stack is the first thing that will be removed. We’ll see an example of this shortly which will hopefully explain things a bit better.
The size of the stack is greatly dependent on your OS, hardware and programming language. And while some languages or operating systems do provide mechanisms to expand the size of the stack at runtime, there are limits, and this is usually not a done thing. So under almost all circumstances you should expect this to remain at a fixed size for the duration of your program.
One important aspect of the stack is that the CPU has more than likely recently accessed your data in order to place it on the stack, so it is also just as likely that the data will be in the CPU cache. Having your data in the cache will usually result in significant performance improvements. Depending on what you’re doing with that data of course. Most importantly the cache is significantly faster than normal memory, as it is situated on the CPU itself. So it doesn’t operate under the same latencies that normal RAM does.
What is the stack used for
One of the primary purposes of the stack is to facilitate function calls.
More specifically, this is where function parameters are prepared before calling the function itself. It is also responsible for holding the function return address, which is the location where the program will jump to once the function ends. The stack is also responsible for holding onto temporary values that only live for the duration of the function.
That was a lot of information to parse, so it might help to see what this looks like in practice.
How the stack works
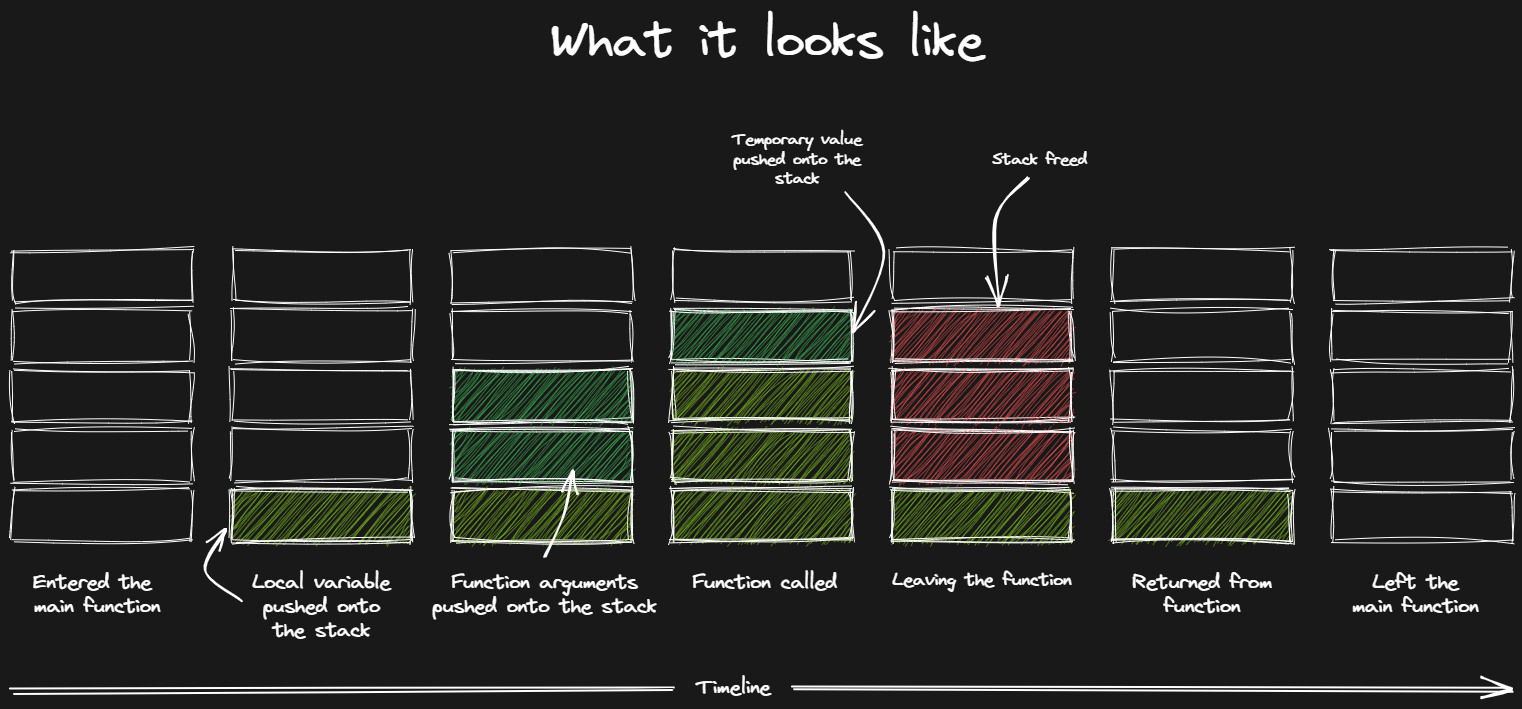
What you see here is just a quick illustration of what the stack might look like for a simple function main that calls another function and then exits.
We start off entering the main function where the stack is empty. We then allocate a small amount of space for a local variable. For example, assigning the integer value 1 to a variable called a.
After that you can see we are allocating more space to prepare to make a call to a function, allocating space for two function parameters.
Once inside the function, we allocate a further chunk to hold a variable local to the nested function. When the function is done, just before returning, we free our stack space. So when we return to the previous function, things are as we left it.
Finally, we leave the main function and the remaining memory is “freed”.
Note: This section has some of those lies I was talking about earlier. There are registers involved in this process too, and quite often it won’t work in exactly this manner, but it illustrates the point so we’ll just leave it at that and move on!
What it actually looks like
void main() {
int numbers[] = {1, 2, 3, 4, 5};
}
This is a C program that assigns an array of five integers to the variable numbers. Lets take a look at a bit of assembly to see how this is represented.
// Allocating space for 5 x 32bit values = 20 bytes
sub rsp, 20 <--- Allocation
...
mov DWORD PTR[rsp], 1 <--- Assignment, increasing by 4 bytes for each value
mov DWORD PTR[rsp+4], 2
mov DWORD PTR[rsp+8], 3
mov DWORD PTR[rsp+12], 4
mov DWORD PTR[rsp+16], 5
...
add rsp, 20 <--- Release
Potentially a bit mystifying looking if you’ve never looked at assembly before, but it is really quite simple.
sub is the instruction to “subtract” and rsp refers to the “stack pointer”. So we have an instruction that is subtracting 20 bytes from the available stack space. This is all we need to do to allocate the space to hold our array of five 32bit integers.
The next five lines copy the values into their respective locations on the stack. You can see we are adding four to the stack pointer each time. 4 bytes for every 32bit integer.
The only real important thing to note here is that both the allocation and the release of the space are achieved in single CPU instructions.
This is why the stack is fast, and this is why it usually is a place you want to have your data when the CPU is doing work.
It is worth stressing that we are not technically allocating, or freeing new chunks of memory here. Instead we are simply changing the spot we’re pointing to in a large chunk of memory that has already been allocated.
What is the heap
Now let’s take a look at the heap.
Unlike the stack, the heap is allocated dynamically at runtime. However, much like the stack, it is also stored in RAM. The main benefit of the heap though is its ability to grow to fit whatever you need as long as you have enough physical RAM to support it.
More importantly the heap is made up of a number of randomly sized small chunks of memory. It is this trait that sets it apart the most from the stack with its single contiguous block. Having its allocations spread around requires a lot of bookkeeping. It needs to keep track of which blocks are used, which have been freed and how much space is still available. It is this management overhead that causes the heap to often be quite a bit slower than the stack, especially for applications which make a large number of allocations at runtime.
Also, the heap can become fragmented over time. As each chunk is freed, it potentially leaves a small gap that may be too small to fit another allocation, effectively rendering the block unusable and akin to a memory leak.
Your OS will employ some techniques that will attempt to deal with these sorts of issues, but this means that each time you request or free a block of memory on the heap, you’re potentially incurring some management overhead, and wasting CPU cycles doing administrative work instead of the work you actually want it to do.
It is important to note that unlike the stack, the memory you request from the heap needs to be freed by you, the programmer. Perhaps more commonly these days, the garbage collector.
What is the heap used for
So what is the heap used for?
Put simply:
- Data that lives longer than the scope of a function
- Data that exceeds limited space available on the stack
- Data whose size can’t be determined until runtime
How the heap works
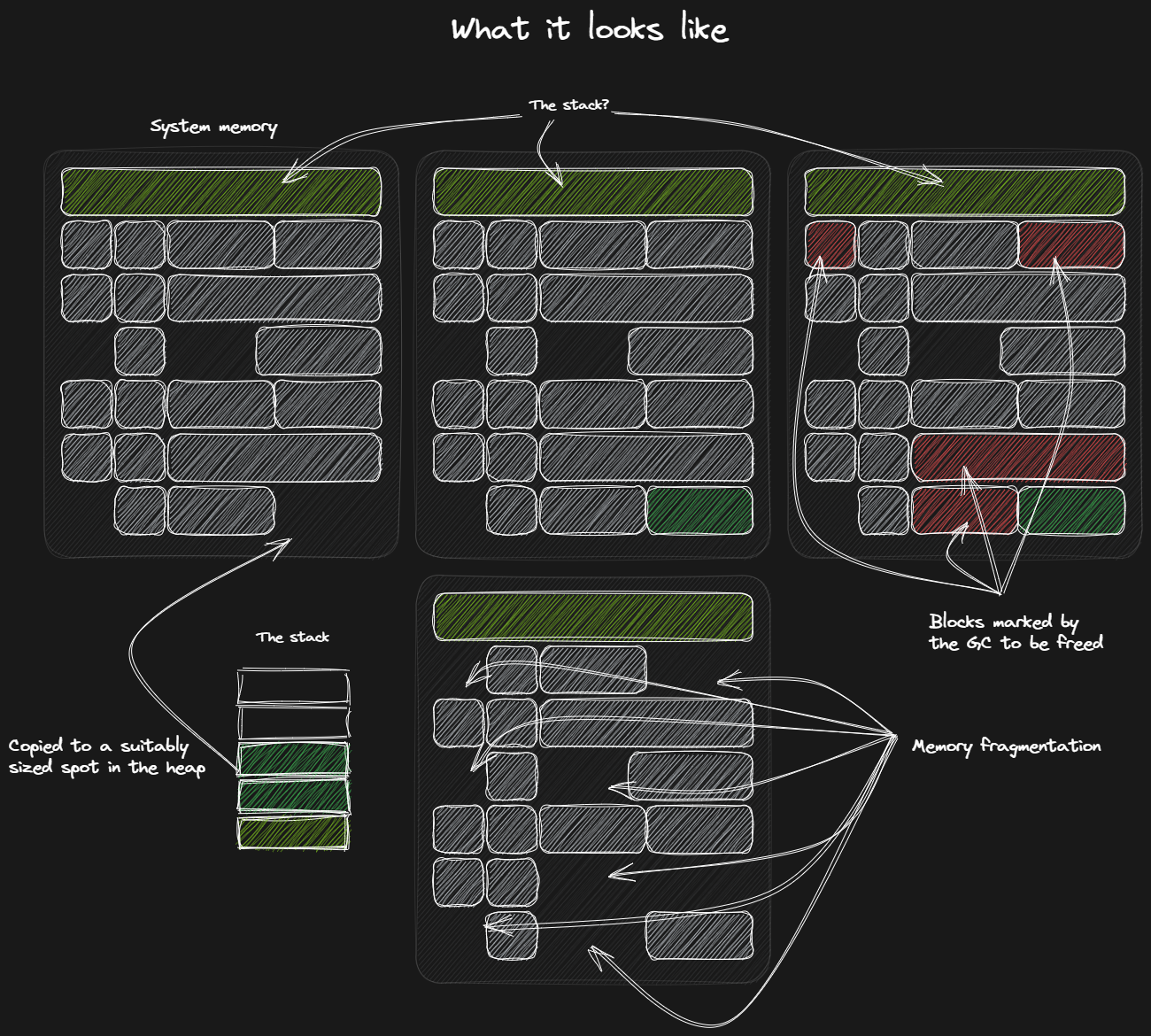
This is an overview of what your system memory might look like when running your program.
You’ll notice the single large block holding our stack. Then we have a number of other randomly sized allocations littered about. These might be ours, but they could also be from another program entirely. Which blocks you get is completely up to the OS.
If you take a look at the bottom left, you can see some data being copied from the stack to the heap. In the center image we’ve allocated some space from the available pool, which now holds our data.
In the image at the bottom we can see what it looks like when a number of chunks have been released back to the OS, illustrating what memory fragmentation looks like.
What it actually looks like
static int values[] = {1, 2, 3, 4, 5};
void heap() {
int* numbers = (int*)malloc(sizeof(int) * LEN(values));
memcpy(numbers, values, sizeof(int) * LEN(values));
}
Once again, this is a little bit of C code.
It is not important for you to be able to read it, you only need to understand that it does mostly what we did in the previous example I showed, where we had some values stored on the stack. However, this time around, much like the diagram in the previous slide, we are taking the data stored on the stack and copying into the heap.
mov rbp, rsp
sub rsp, 16
mov DWORD PTR [rbp-4], 5
mov eax, DWORD PTR [rbp-4]
...
mov rdi, rax
call malloc
mov QWORD PTR [rbp-16], rax
...
mov rax, QWORD PTR [rbp-16]
mov esi, OFFSET FLAT:values
mov rdi, rax
call memcpy
And here is the assembly for that.
Firstly, we allocate a bit of stack space for the operations we’ll need to perform in this function totalling 16 bytes. We then load the length of our array onto the stack and execute a few more instructions to setup the data required before we make our call to malloc.
Out of that comes our address to the block of memory we’ve been given, stored in the rax register. We then use that bit of information to copy our values onto the heap by calling memcpy. If you’ve used C at all, you should definitely be familiar with these two functions.
Importantly you won’t see any reference to the heap memory being deallocated here. This is something we’ll need to call manually at some point in our program. At the moment we have a memory leak.
I would like you to note the call to malloc here though, and urge you to take a look at its glibc implementation in your own time. This is likely what your program will use when requesting memory from the OS on Linux based machines.
A quick summary though:
- 40 functions
- 20 data structures
- multiple source files
- approximately 20,000 lines of C code
When I mentioned that allocating memory on the heap was complicated and had a fair amount of administrative overhead. This is what I meant.
Keep this in mind each time you allocate some memory on the heap.
When is the stack or the heap used?
System programming languages like C or Rust, tend to offer the programmer fine grained control over where data is stored and when it is cleared. Managed languages like JavaScript or C# can tend to be somewhat less deterministic. While they do occasionally offer the ability to be explicit, these are often just suggestions to the compiler, which they may choose to ignore.
Managed languages like JavaScript tend to store much more in the heap, as they like to be less strict about the lifetimes of your data. So instead of potentially freeing the data when your function ends, a garbage collector will instead come along later and free it in its own time.
The takeaway
So a quick summary of what we’ve covered so far.
- Both the stack and the heap live in RAM (usually)
- Differ in how they are managed
- Differ in what they are used for
- Differ in their performance profile
- Stack are managed for you
- You (or the GC) are responsible for releasing heap allocations
This has obviously been a greatly simplified explanation. The important point to convey here is that the heap is what you as a programmer need to be concerned with, or more accurately the garbage collector does.
What does a garbage collector do?
Just a warning. I am going to refer to the garbage collector as the conglomeration of systems which are responsible for managing the heap on your behalf. Technically the GC is only really interested in cleaning up your mess, but it is easier to just use it as a catchall for the rest of the systems involved here too.
So the garbage collect/memory management systems tend to do the following:
- Allocates and manages the heap for you
- Reference tracking
- Identifies garbage
- Reclaims garbage
The garbage collector, or heap management systems are responsible for acquiring memory from the OS, tracking its use, and then freeing it up again when you are done using it.
Downsides of a garbage collector
While the garbage collector does afford you some freedoms, as with all things, it comes with some costs.
They are highly complex systems which run alongside your application, constantly monitoring when and where memory is accessed, looking for opportunities to reclaim any chunks that are no longer in use, and to deal with any issues that arise from its general operation.
The “mark-and-sweep” technique is one of the more common methods employed by garbage collectors. As the name suggests, it consists of two phases: marking and sweeping. During the marking phase the GC identifies and marks all active references to memory throughout your program, starting from the root stack and global variables. During the sweep phase the GC will scan the heap, freeing any unmarked (unreachable) chunks. This process may require pausing your program entirely, which can result in a negative impact on both the user experience and the performance of your program. This is of particular concern in real-time applications such as video games.
Garbage collectors are also prone to memory fragmentation. This can occur when you request a new block of memory, but the existing available chunks aren’t large enough. In this situation this free block will be ignored and instead you will be allocated an entirely new block elsewhere in RAM, potentially leaving this free block unallocated.
It is important to note that even though this block of memory is no longer being used, it might still be owned by the GC, thereby making it unavailable for use by other programs on your system. If enough fragmentation occurs, you can eventually arrive at a situation where the entire system is starved for memory.
GCs employ a number of techniques to address these fragmentation issues, one of which is compaction. This is where the GC will identify small gaps between allocations and rearrange memory to consolidate them, reducing the fragmentation. However, this can be a computationally expensive operation, and therefore potentially problematic in an environment where performance matters.
Let’s take a look at some Rust
So keeping that all in mind, let’s take a look at some Rust.
But first, some TypeScript…
let v = ["1"];
let a = v[0];
console.log(`a=${a} v=${v}`);
In this extremely simple code snippet we are constructing an array of strings. We then assign the first element in the array to a and then print out some information about our current state.
a=1 v=1
There should be nothing surprising or unusual in this bit of code, and the output is pretty much as we would expect.
The same in Rust
This bit of Rust illustrates basically the same bit of logic as the TypeScript one.
let v = vec![String::from("1")];
let a = v[0];
println!("a={} v={:?}", a, v);
It constructs an array of strings and assigns it to v. It then assigns the first element in the array to a, before finally printing out the result, the same as before.
With one exception. It doesn’t compile.
error[E0507]: cannot move out of index of `Vec<String>`
--> src/main.rs:3:14
|
3 | let a = v[0];
| ^^^^ move occurs because value has type
`String`, which does not implement
the `Copy` trait
|
help: consider borrowing here
|
3 | let a = &v[0];
| +
For more information about this error,
try `rustc --explain E0507`.
For those of you with some experience in Rust the issue here is obvious, but for those coming from a background in more forgiving languages, this can seem strange.
Put simply, when you assign the first element in the array to a, you are telling the compiler to move that value out of the array, and assign it to a instead. Technically this isn’t actually what is happening, and the value still resides in the same location in memory, but as far as the Rust borrow checker is concerned, you have moved that value. So any reference to v is now invalid, since it can no longer guarantee what is in the array that v is assigned to.
Aquascope
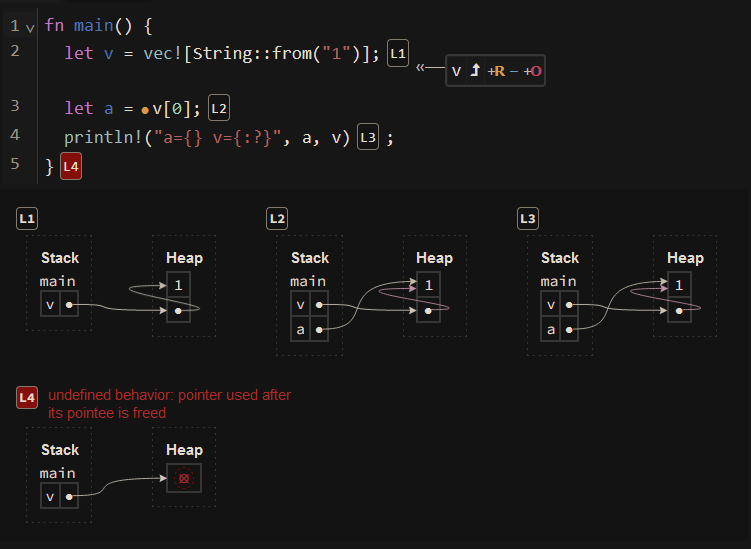
Rust has a few fairly helpful tools in its ecosystem. This is one called aquascope, and it allows you to visualise how your Rust code is being interpreted by the compiler.
At line one we can see that v is a pointer to an address on the heap, and that the first element in the array is 1. On line two we can see that v is still pointing to the same location, however, a is now also pointing to the first element of the array. Finally we can see that v is now marked as “invalid”.
The fix
So how do we make this compile?
let v = vec![String::from("1")];
let a = &v[0];
^
println!("a={} v={:?}", a, v);
We simply need to tell the Rust compiler that we only want to borrow the value.
Without the borrow symbol, we are telling the compiler that we want to move the first element out of the array and assign it to a. But now with the new symbol in place, we are instead asking for permission to use the value for a short period of time, after which we’ll return it to its original owner.
a=1 v=["1"]
With the fix in place, we now get the expected outcome.
It is important to note that the vector, or list of strings here, is actually allocated on the heap, but Rust is able to tell us at compile time, that we are potentially doing something wrong by pointing at the same block of memory from two separate locations, so it instead interprets it as a move.
What we are doing wrong specifically here is not terribly important, and there is plenty of material around that will give you a good explanation on how the borrow checker works and how to work with it. What is important though to understand that Rust is primarily interested in both who owns data, and how long that data lives for. And unlike a garbage collector, it is able to do this at compile time.
What about smart pointers in C++?
Can’t languages like C++ already track ownership with the use of “smart pointers”, without using a garbage collector?
Yes they can, but Rust’s primary selling point is its combination of ownership tracking, along with a strong static analysis of data lifetimes. That, and C++ also allows you to bypass the “smart pointers” without invoking the wrath of the compiler. Doing the same in Rust is not quite as easy, and tends to be very visible when you do so.
What is a lifetime?
I mentioned lifetimes as being an important part of what Rust does, but what are lifetimes?
A lifetime is what Rust uses to express the scope, or period of time, for which a reference to a value remains valid.
It is this concept that also allows Rust to prevent issues that are fairly common in other systems level languages. Such as use-after-frees, dangling references and data races.
fn main() {
let a = String::from("testing");
}
Here, a is valid for the duration of the function main, or more accurately, it is alive for only a single line. Where normally we would consider the variable freed at the end of the scope, here Rust knows that a is not being used after the line it is initialised on.
It is also important to note that the String type here is allocated on the heap.
fn main() {
let a;
{
let value = String::from("testing");
a = &value;
}
println!("{}", a);
}
Here is another example.
For those who haven’t used slightly stricter languages before, value here ceases to exist once we leave the nested scope, so you would normally expect to see a compiler error if you tried to access it outside of that scope.
We also let the compiler know that we want to use the variable a for the entire scope of main, rather than just inside the nested scope.
In most languages, this would work just fine. The garbage collector would see that we’ve made another reference to the string, and it would keep it alive for the remainder of the function.
But Rust will complain.
error[E0597]: `value` does not live long enough
--> <source>:37:7
|
37 | a = &value;
| ^^^^^^ borrowed value does not live long
enough
38 | }
| - `value` dropped here while still borrowed
39 |
40 | println!("{}", a);
| - borrow later used here
It knows that we are assigning a to the borrowed value, and since value doesn’t live beyond the nested scope, when we try use a on the last line, we get a compile time error.
Rust’s major innovation
It is a combination of tracking the ownership of data, and how long that data lives “at compile time”.
This is Rust’s major innovation.
So what?
“So what?” you say.
Being able to do this at compile time means that Rust doesn’t need to add any additional CPU instructions to manage this memory. Yet, you as a programmer still have complete control over when and where memory is both allocated and freed.
Historically you needed a garbage collector for this kind of freedom, but as covered earlier in the article, those come with a runtime complexity and performance cost. Rust asks for neither.
It does have a cost though.
It comes in the form of shifting a bit of that complexity back onto the programmer. In most situations the compiler can infer what you need, but in a few it cannot, and when that happens you’ll need to step in and help it out by providing extra information, or by altering your code.
It is important to note that this complexity does decrease over time. Eventually you’ll get use to its idiosyncrasies and you’ll likely be back to being as productive as you were with any other language. With the added benefit of the borrow checker helping you to identify bugs that you might not have otherwise found until runtime, if at all.
Do I recommend Rust?
So that’s it. That is mostly what I wanted to cover here, but that leaves one big question.
Would I recommend Rust?
Rust is possibly my most used language on hobby projects, and has been since around 2015 when I first started following its progress. It is one of about three languages I usually pick from when starting a new project. (Rust, C and Zig)
But do I recommend it? I’m not completely sure.
Even though Rust does make some amazing guarantees at compile time, there is something about it that always bugs me whenever I use it. I tend to find myself constantly solving “Rust” problems, rather than my actual problems. Even small distractions of this nature can take you completely out of the flow, even if you know what you’re trying to do is technically safe.
This is because what Rust considers safe, does not necessarily encompass all possible safe programs. Instead it can only cover a subset.
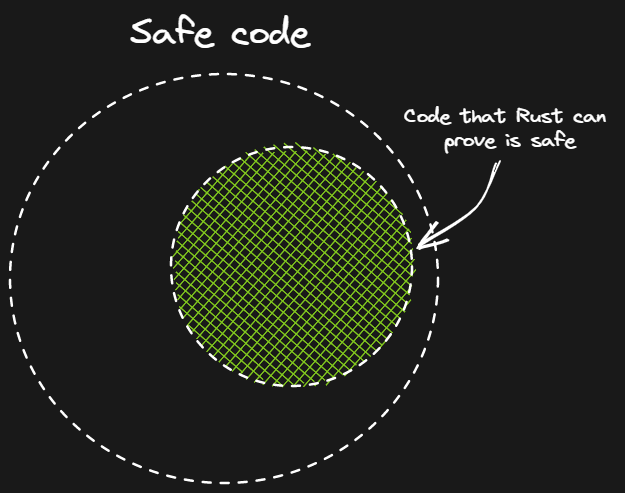
For the rest, Rust will need you to alter your solution, or at least annotate it in such a way that it understands what you’re trying to do. And it is this extra bit of effort that causes me some frustration.
Having said that though, I do think that Rust will likely play a major role in the commercial landscape in the future. Especially in areas where performance matters. Perhaps eating a lot of the roles that C++, Java or C# would have otherwise been a natural fit for. There are already a number of large companies using it for some of their new projects. “Safety” is an extremely marketable feature, and often that is enough, even without the performance gains.
However, not everyone needs to constantly write “safe” software, so on a personal level, I do find the added complexity Rust brings to occasionally spoil the fun. Especially when I’m just trying to prototype something.
But does Rust deserve some of your time at least? Absolutely! It is one of the best, if not the best programming languages to come out in the last two decades. If nothing else, it will change the way you program in other languages in the future.
For me that is enough to consider it worth at least a bit of your time.